Az „Excel” fórum célja, hogy keretet adjon az Excel felhasználók széles táborának tapasztalataik megosztására, és lehetőséget a segítséget kérőknek. Az alábbi összefoglaló azért készült, hogy segítse a helyes kérdésfeltevést.
– Írd le szabatosan a problémát. Úgy fogalmazz, hogy ne csak te magad, de a szakértő is megértse, mire szeretnél választ kapni.
– Írd le, hogy milyen verziójú Excellel dolgozol. (Vagy ha nem – ill. nem csak – Excel, akkor micsoda?)
– Írd le, hogy milyen úton indultál el, és hol akadtál el rajta.
– A kérdés megértése szempontjából sokat segíthet, ha feltölteszt egy képet, amin látszik, hogy mit szeretnél, vagy illusztrálja azt.
– Még jobb, ha feltöltesz egy minta munkafüzetet valahová (pl. data.hu). Feltöltés előtt távolítsd el belőle a nem publikus adatokat.
– Ha a feladat jellege olyan, célszerű az "előtte" és "utána" állapotokat bemutatni. (Miből kellene csinálni mit?)
– Ha VBA kódon kell javítani, másold be a releváns kódrészt. Rövid kód mehet hozzászólásba, hosszú kód inkább ide: http://pastebin.com/
– Ha valami nem úgy működik, ahogy kellene, add meg a rendellenes viselkedés jellemzőit, a hibaüzenetet, és a hibát okozó programsort.
Szeretném megkérdezni, hogy egy összetett táblázatot tartalmazó oldalakon, ahol vegyesen vannak védett és nem védett cellák is "össze-vissza"; valahogy ki lehet-e mutatni, hogy melyik cella védett, és melyik nem. Szeretném ezt tenni ellenőrzés céljából a táblázat elkészítése után, hogy ne próbálgatással kelljen megnéznem, hogy a megfelelőeket védtem-e le és amit kell, azt szabadon hagytam-e. Lehet ez egy lista, vagy kiszínezés, vagy hasonló, ahol áttekintően látom, hogy jól dolgoztam-e.
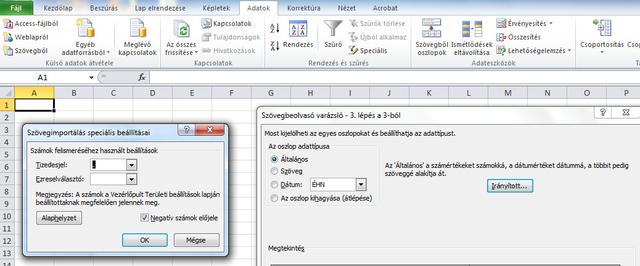
Esetleg próbáld meg a szövegfájl beolvasását a felső menüben az Adatok->Külső adatok átvétele menüben a szövegből történő beolvasással megnyitni.Itt az adott oszlopnál az 'irányított' gombra kattintva ki tudod választani a beolvasandó fájlban használt tizedespontot:
Köszönöm! Nem egyszerű, mert vannak üres cellák is (bár ezekkel nincs gond) és szöveges cellák is vannak, miközben mindent (a számokat is) szövegnek vesz az Excel. Még töprengek egy gyors és egyszerű módszeren. A tipp mindenesetre hasznos, köszönöm!
A Val() függvény jól megérti a tizedespontot, szóval ha tutibiztos, hogy a szöveges értékeid kizárólag tizedespontot tartalmazó számok, akkor megteheted azt, hogy cellánként lecseréled az értéket:
cella.Value = Val(cella.Value)
Így biztos, hogy a cellában szám lesz, és csak a megjelenési formája függ az adott gépen érvényes területi/nyelvi beállításoktól.
Vannak nyers adataim (egy más szoftverből kapott kimeneti szövegfile-ban), amit Excel-ben szeretnék tovább feldolgozni és kiértékelni. A tizedespontok a szövegfile-ban '.' ám nálam az Excelben ',' kellene legyen. Egy trükkös megoldást találtam (még régen ti mutattátok itt, azóta is használom):
Sub SetFormat() Dim Displ As Worksheet For Each Displ In Worksheets With Displ If Not .Name = ExpJointsName And Not .Name = ResName Then .Columns("B:G").Replace What:=".", Replacement:=".", LookAt:=xlPart, _ SearchOrder:=xlByRows, MatchCase:=False, SearchFormat:=False, _ ReplaceFormat:=False .Columns("B:D").NumberFormat = "0.000" .Columns("E:G").NumberFormat = "0.0000" End If End With Next Displ End Sub
Ez bár működik, de gyanítom, hogy más Windows-os területi beállítások mellett nem fog működni! Mit kellene tegyek, hogy a szövegfile '.' tizedespontjával megadott számértékeket az Excelben minden tizedespont beállítás mellett számkért értelmezve tudjam kezelni? A Replacement:="." helyett kellene valami univerzálisabb megoldás. Talán le kellene kérdezni az aktuális beállítást, mi a tizedespont, és ha az nem '.' (ami a nyers adatokban), akkor arra cserélni a nyers adatok tizedespontjait, amit az Excel elvár. De ezt hogyan?
Bár a HA függvény látszólag adja magát, és elsőre talán logikusnak tűnik a használata a feltételes formázásban, valójában egyáltalán az.
A feltételes formázás képletének egy logikai IGAZ vagy logikai HAMIS eredményt kell adnia, ez alapján vagy érvényesül a megadott formázási szabály, vagy nem.
Viszont a HA függvény maga is azt csinálja, hogy kiértékel egy feltételt, és a feltétel teljesülése esetén az egyik, nem teljesülése esetén a másik értéket adja vissza eredményként.
Így ha eleget akarunk tenni a feltételes formázás elvárásainak, tudniillik, hogy a képletünk IGAZ/HAMIS eredményt szolgáltasson, akkor a HA függvényt csak az alábbi formában tudjuk használni:
=HA(<valami feltétel>;IGAZ;HAMIS)
Ám itt valójában semmi mást nem teszünk, mint hogy kiértékeltetjük a feltételt a HA függvénnyel, teljesen feleslegesen, hiszen ugyanezt a kiértékelést a feltételes formázás szabálykezelője is el tudja végezni. Tehát eredményét tekintve a fenti képlet egyenértékű azzal, hogy teljesen elhagyjuk a HA függvényt:
=<valami feltétel>
Összefoglalva: a HA függvény használata a feltételes formázásban nem tilos, működik is, viszont felesleges, mert csak bonyolultabbá teszi a képletet, lassítja a végrehajtást, és eltereli a figyelmet a lényegről, mely utóbbi a <valami feltétel> szabatos megfogalmazása lenne.
Szeretnék segítséget kérni feltételes formázással vagy egyéb módon hogy tudom megoldani egy táblázaton belül hogy minden második sor háttere legyen szines, de csak akkor ha a sor valamely cellája értéket tartalmaz.
Köszi a hozzászolást megoldódott, nekem valahogy nem esett le ez a szöveges dolog.
A hiba az volt hogy a táblázatban az összes adat mögött ott volt a "g" gramm emiatt beolvasta de nem adta össze, miután kitöröltem a szöveget a bázis táblából így már összeadja és a cellaformázásnál pedig beállítom a számot egyénire mögé írva egy "g" ot és tökéletes kiadja amit akarok.
Nem jártam messze tőle de nem esett le szóval köszi még egyszer.
Amúgy valóban számok vannak azokban a cellákban? Attól hogy egy érték az FKERES függvény eredménye, attól még a SZUM függvénynek vígan össze kellene adnia, feltéve, hogy szám. De pl. olyat, hogy 17g + 92g + 32g, olyat nem fog a SZUM összeadni, mert ezek szövegek, nem számok.
(Fura ez, mert aki legördülő listát létre tud hozni, annak a fentieket csípőből vágnia kellene, de a kérdésed megfogalmazásából nekem ez jutott eszembe.)
ebből az adathalmazból csináltam egy legördülő listát majd a mellette lévő cellákba az "FKERES" függvénnyel beolvastattam a hozzá tartozó fehérje szénhidrát stb adatokat
Mivel étkezésekre van bontva pl egy étkezés 6 sort tartalmaz ahova mindenki beirhatja hogy reggeli pl eszik kenyeret joghurt zabpehely stb a végén szeretném összeadva látni hogy az étkezés mennyi fehérjét zsirt tartalmaz de a "SZUM" függvény nem veszi figyelembe mivel amiket összekéne adnia cellákban ugyan én látom az értéket de valójában ugye az "FKERES" függvény van benne.
Van e valakinek valami ötlete hogyan lehetne az Fkeres által kiadott eredményeket összeadni illetve megszorozni pl.
Na egy ilyen ember előtt én is leborulnék. Einstein sem tudná eldönteni az 123,123 karaktersorozatról (ha csak ennyit lát), hogy az mi is valójában.
Annak mondjuk van némi realitása, hogy a szövegkörnyezetet megvizsgáljuk programmal, és abból következtessünk. Ha pl. a forrás szöveg kizárólag olyan - felismerhető - számokat tartalmaz, amelyeknél a tizedesjel pont, akkor feltételezhető, hogy az 123,123 is ilyen, csak nincs tört része. De csak feltételezhető. Mert mi van, ha ez itt épp egy kivétel. Tegyünk a kódba szövegértelmező algoritmust is? Hát... akkor már inkább ráhagyom a felhasználóra a döntést.
Ember legyen a talpán, aki teljesen kötetlen szövegre talál erre egy biztos algoritmust, ami jól behatárolja az előjelet, helyiértéket, tizedeshelyet (Regexszel)
Elég sokat izzadtam a témával, és nem sikerült megtalálnom a bölcsek kövét.
Valóban akkor van a legnagyobb probléma, ha az egy szem tagolójel után még három számjegy jön.
De egyéb esetekben is előfordulhat, hogy olyan helyesírási hiba van a számban, amit a humán olvasó a szövegkörnyezet alapján tud korrigálni, vagy olyan, amit a humán olvasó sok utánjárással tud dekódolni, de gépi átalakításkor bizony információt veszíthetünk. Ha egy jól definiált speciális esetet meg tudsz oldani, már vállon veregetheted magad.
Igazából rövid távon nem gond, mert a szövegfájlokat, amelyeket fel akarok dolgozni, programok állítják elő, és így egész korrekt feltételezéssel tudok élni mindegyik esetben. Csak szerettem volna egy általánosabb megoldást, amit egy ctrl+c/ctrl+v kombóval be tudok tenni akármelyik későbbi programomba. De odáig nem terjed az önbizalmam, hogy majd pont én fogom megírni a Nostradamus-algoritmust, szóval a nem szabályos alakokat valószínűleg kivételként fogom kezelni. Meglátjuk.
Sehogy. Csak feltételezéssel vagy manuális jelöléssel tudsz élni, esetleg a szövegkörnyezetből találod ki... Üdv az aknamező közepén. Vedd hozzá a nem szabályos alakokat is, mert az emberek többségének rossz a helyesírása, és összevissza írogatnak számokat is.
Igen, köszönöm, erre közben rájöttem, és mindegyiknek elé tettem ezt: -?
Most azt nem tudom, hogy hogyan állapítsam meg, hogy pl. a "123,123" sztringben a vessző tizedesjelet ábrázol (magyar), vagy ezres szeparátort (angol).
Dolgozom egy kódon, ami tetszőleges, számot ábrázoló sztringből numerikus értéket (számot) csinál. Ehhez először is meg kell állapítani, hogy a sztring valóban számot takar-e, mert hátha nem. Az is cél továbbá, hogy magyar és angol számábrázolások felismerésére, konvertálására egyaránt alkalmas legyen. Úgyhogy ma kicsit elmélyedtem a Regular Expressions világában, és a szám-jelölt sztringek tesztelésére az alábbi kifejezéseket hoztam létre (remélem jól jeleníti meg a motor...):
Igen, naluk meg az ertelem az elso, es ahogy anno a matektanarom is mondta, az ertelem elso lepese, hogy valaki kepes elmondani, hogy mit nem ert.
A kisiskolasok gyorsan rajottek, hogy az abrat negy reszre bontva lehet gyorsan szemleltetni, pl. igy:
1. A-nak B, annak C, annak F teljes resze
2. A-nak D teljes resze
3. A-nak E, annak G teljes resze
4. H-nak I teljes resze
A vegen A-t kell H-val valahogy osszevetni, ami mar bonyolult.
A kerdesem ennyi volt, hogy ilyen feladat eseteben hogyan lehet az ilyen fuggosegeket gyorsan vizualisan megjeleniteni, de ugy tunik, halmaz abrazolasnal tovabbra is a max. 3 halmaz a dominans Excelben, igy nem alkalmas ra.